AI Paper Review/MLLMs
[CVPR 2024] CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update 리뷰
jiminai
2024. 8. 15. 03:13
반응형
Abstract
- 기존의 training 기법들은, 활용되는 tool에 대해 freeze를 하여 학습을 진행했지만, 이는 continual learning을 간과하였다고 봄.
- 이에 따라, Inference, Reflection, Learning phase 총 세 단계를 거쳐 새로운 지식을 습득하는 환경을 조성할 수 있는 closed-loop learning framework인 CLOVA를 고안해 냄
- 3단계의 phase
- Inference phase : LLM이 할당된 task에 맞게 그에 맞는 tool들을 실행한다
- Reflection phase : Multimodal이 전체적으로 human feedback을 하면서, tool들을 update한다
- Learning phase : 자동적으로 training data를 모으고 tool들을 update함으로써, CLOVA가 효율적으로 새로운 knowledge를 습득할 수 있도록 함
Introduction
- Q. tool이란 무엇인가?
- A. 예를 들어 보자.
”What is the person to the left of the umbrella doing?” 이라는 쿼리가 들어오면, MLLM은 다음과 같은 절차를 밟는다.- detection tool을 이용해 umbrella를 찾고,
- umbrella의 왼쪽 지역에 대한 image를 crop하며,
- detection tool을 이용해 umbrella 왼쪽에 있는 사람을 찾아서,
- VQA tool을 통해, “What is the person doing?” 이라는 질문으로 다시 바꿔서 더 쉬운 방식으로 물어보게 된다.
- CLOVA에서 사용된 tool들

- 그렇다면, 이렇게 closed-loop learning framework의 challenge는 없을까?
- 당연 있다!
- multi-step으로 구성돼 있고, 에러의 종류가 다양해서 update되는 tool들을 identify하는 작업은 어렵다.
- 학습할 지식은 예측할 수 없기 때문에 훈련 데이터를 자동으로 수집하는 것이 필요하다
- 기존의 visual tool들은 큰 Neural Network를 가지고 있는데, 이는 update를 할 때에 비효율적이며, 단순히 naive한 fine-tuning을 거칠 경우 forgetting 문제가 발생하는 등의 updating obstacle이 발생할 수 있다.
- 이러한 challenge를 해결하기 위해.. (Detail들은 추후 서술)
- Multimodal global-local reflection 적용
- 세 가지 data collection 방법론이 제기됨
- training-validation prompt tuning을 통해, tool을 update함 (즉, 원하지 않는 response를 하는 prompt는 버려지고, 옳은 Response에 대해서만 data를 collect함)
Method
- 전체 Framework는 다음과 같다.

- CLOVA는 3 phases로 구성된다.
- Inference

- Plan Generation
- $D = \{D_{p,s},D_{p,f},D_{c,s},D_{c,f}\}$ = {plan generation(correct/incorrect), program generation(correct/incorrect)}
- BERT 모델 사용하여 주어진 instruction에서 feature 추출
- plan generation example에서 비슷한 example들을 가져와서, prompt를 만든 뒤, LLM에 태워서 plan을 generate함
- Program Generation
- Plan Generation과 비슷한 방식임
- Tool Execution
- Interpreter module 사용 : program parse, tool들 추출
2. Reflection

- Inference에서 task가 제대로 해결되지 않았으면 Multimodal global-local reflection 진행
- Result Conversion
- 기존의 visual 결과들을 BLIP 모델을 통해 text form으로 바꿈 (captioning)
- Global Reflection
- Instruction, Plan, Program, result 에 대한 global prompt를 LLM에 태워서, criitique만듦
- Local Reflection
- global reflection에서도 실패했다면, local reflection 진행.
- 한 step에 해당하는 부분을 checking
3. Learning
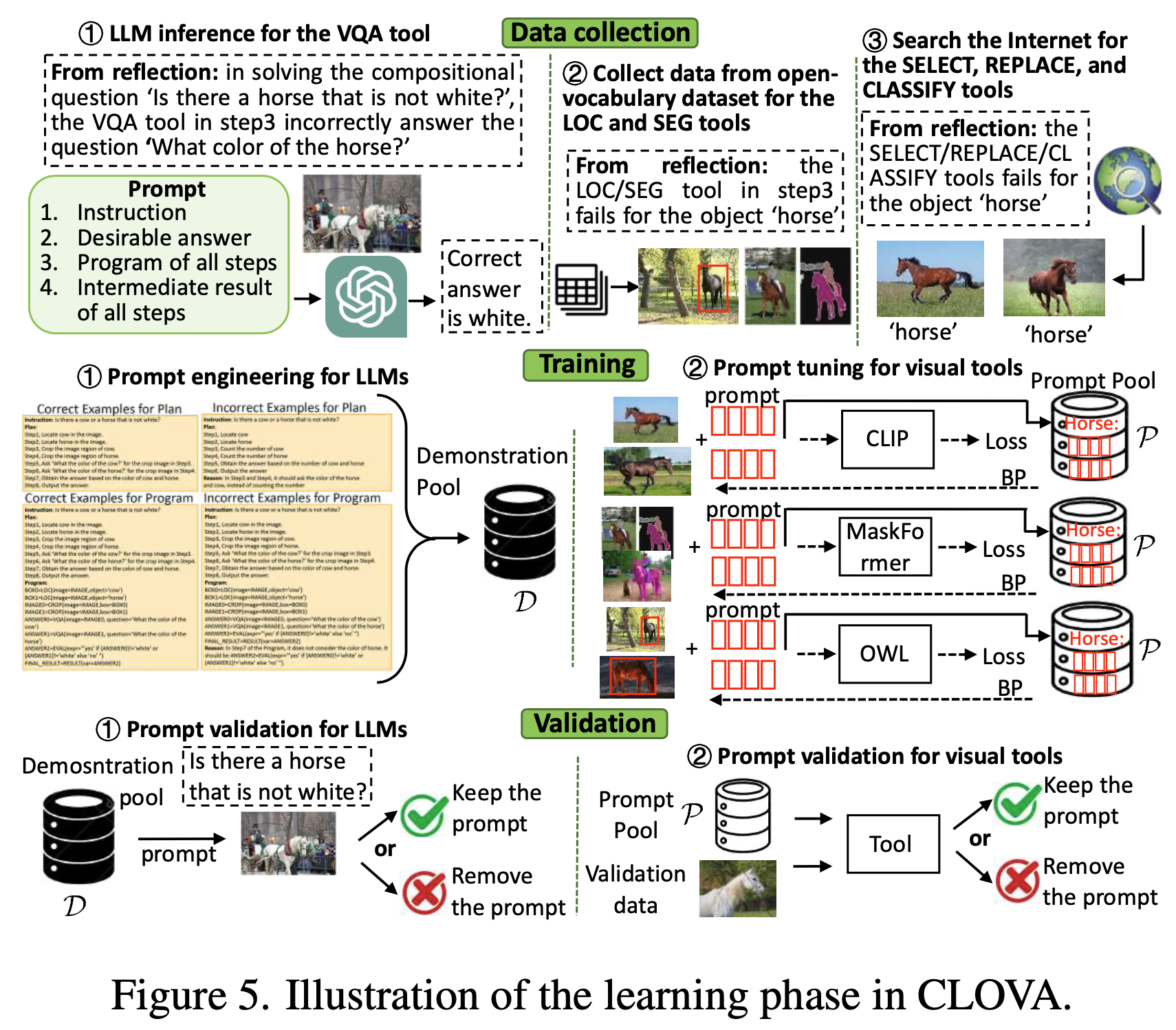
- reflection을 통해 update가 필요한 tool을 Identify했다면, 이제 learning phase를 통해 training data를 모으고 training-validation prompt를 통해 tool들을 update한다.
- Data collection
- tool들마다 update하는 방식이 다르기에, 다양한 방식으로 data를 모음
- VQA tool을 위해 LLM에서 training data(question, answer pair) 얻음
- LOC, SEG tool을 위해 open-vocabulary visual object grounding dataset에서 얻음.
- SELECT, CLASSIFY, REPLACE tool을 위해 internet(google)에서 data얻음
- Prompt tuning and validation
- tool을 update하기 위해서는 , prompt tuning도 필요.
- 각각의 training instance(이전에 성공했던 visual tool들 -fail한 tool제외)에 대한 prompt 각각을 가져와서, collect한 뒤에, 각 tool들이 desirable한 결과를 내는지 확인.
- 정답 결과를 내지 않는 prompt는 버리고, 정답 prompt만 data collect
- 이렇게 진행해서, 각 tool에 대한 prompt pool $P$를 얻음
- 이렇게 training과 validation을 거치면, 해당 Pool에는
- Prompt ensemble
- 이렇게 학습된 prompt pool $P$ 를 바탕으로, prompt ensemble 진행
- 예를 들어, “Replace the dog with a cat” 라는 image editing task가 있다면, dog를 SELECT, SEG해야 하고, cat을 REPLACE tool을 사용해야 한다.
- 각 tool을 사용하는 step에 따라, 만약 visual concept가 기존 $P$ 에 존재한다면 $P$에 있는 similar feature과 input image에 대한 feature 의 cosine similarity를 계산해서 prompt를 합친다.
Results
Discussion
Q. 너무 LLM에 의존하는 것 같지 않은지.. 매 순간 prompt를 LLM에 태운다고 했는데, 거기서 잘못된 경우도 있지 않을까? LLM 성능에 대한 의심
Q. Reflection에서, global and local 의 의미는 무엇인가?
반응형