AI Paper Review/MLLMs
SlowFast-LLaVA: A Strong Training-Free Baseline For Video Large Language Models 리뷰
jiminai
2024. 8. 3. 01:11
반응형
Paper Link : https://arxiv.org/pdf/2407.15841
2024-07-22 introduced
Abstract
- 학습 없이도 세부적인 공간 의미와 장기적인 시간적 문맥을 효과적으로 caputre 가능
→ computation resource, model training time 줄일 수 있다! - Slow와 Fast 두 개의 stream design을 사용하여 비디오 프레임의 feature을 aggregate
- Slow pathway는 낮은 프레임 속도로 공간 세부 사항을 유지하며 feature을 추출
- Fast pathway는 높은 프레임 속도로 움직임 단서를 capture

- 기존 challenge :
- input video 넣을 때 frame 수 제한 (e.g., 6 for IG-VLM (Kim et al., 2024) and 16 for PLLaVA (Xu et al., 2024))
- 적절한 temporal modeling design 없이 video feature를 LLM에 넣고..
- motion pattern modeling하는 데에 LLM에만 거의 의존하는 경향이 있음.
Visualization
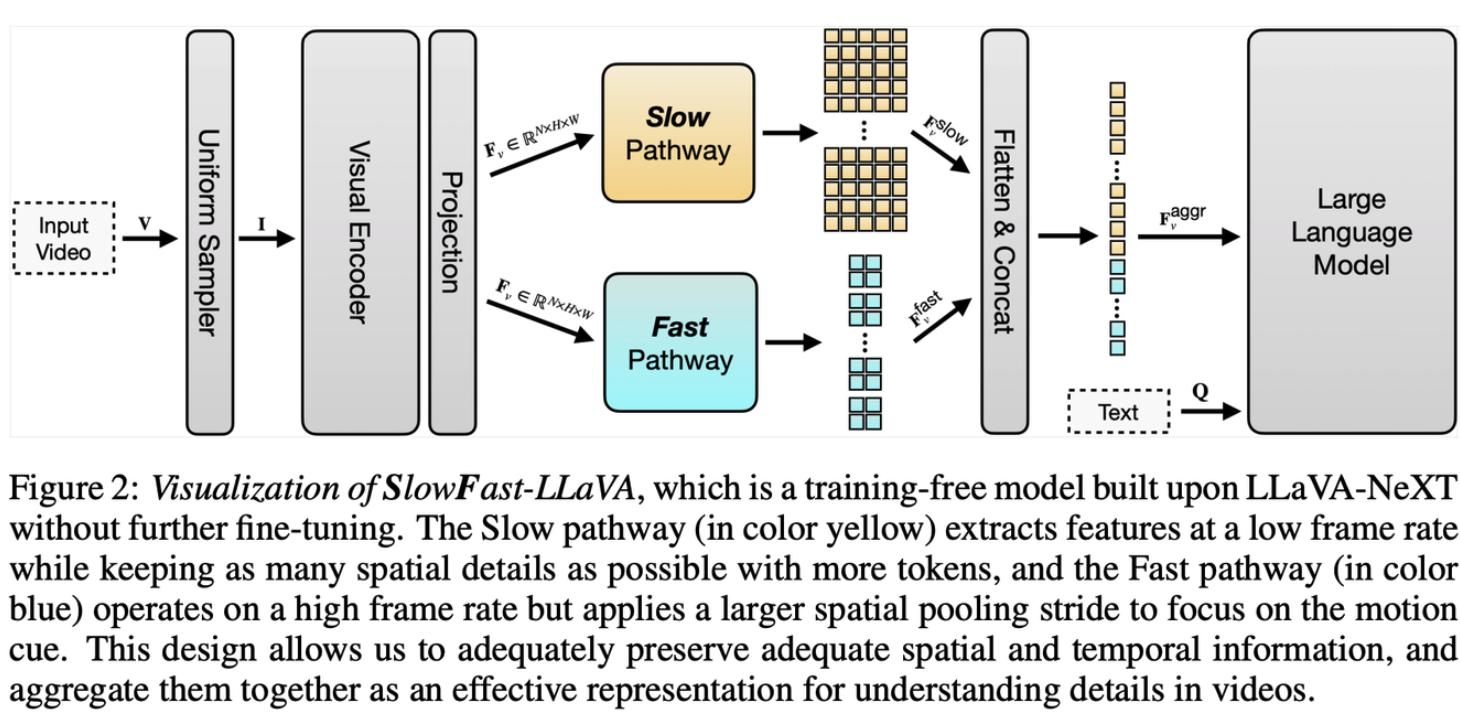

- Terminology 정리
- $I$ : a frame sampler first selects N key frames
- $F_v = Visual_{enc}(I)$ : video features
- $F_v^{aggr} = Aggregator(F_v)$ : visual feature를 aggregate하는 과정 → pooling operation을 통해서
- temporal prior knowledge leverage 가능
- video token을 줄여서, LLM의 token 제한을 피할수있음
- SF-LLaVA의 특징
- training-free model : LLaVA-NeXT에 기반하여 만들어진 model
- Slow와 Fast Pathway를 통해서, spatial & temporal information 보존이 충분히 가능 + 이를 aggregate함으로써 더 효과적인 video understanding 가능
- 두 가지 Pathways
- Slow Pathway
- extracts features at a low frame rate while keeping the spatial details at a higher resolution
- 8 frames each with 24 × 24 tokens
- Fast Pathway
- operates on a high frame rate but uses an aggressive spatial pooling stride
- downsampling each frame to 4 × 4 tokens
- Slow Pathway
- 장점
- slowly changing visual semantics + rapidly changing motion dynamics
- 이를 통해 video understanding 좋다!
- dual-pathway design → modeling capacity & computational efficiency에 좋다
- Detail유지를 위해 더 많은 input video frame 을 넣을 수 있도록 만들어줌
- slowly changing visual semantics + rapidly changing motion dynamics
- Process
- Uniformly sampling a large # of video frames
- visual encoder( CLIP) 을 통해 frame feature 추출
- feature들은 slow와 fast pathway로 분리돼서 들어가게 되고fast pathway는 들어온 feature 그대로 다 들어오게 함 (aggressive spatial pooling → 더 나은 temporal resolution 가져오기 위함)
- 이때 slow pathway에서는 들어온 feature에서보다 더 적은 양을 pooling 하고(이렇게 해야 efficiency와 robustness 좋다고 함)
- 이렇게 두 pathway에서 나온 visual token들은 concat되어 LLM으로 들어가서 answer를 얻어냄
- Results
- 3가지 task 들 : Open-Ended VideoQA, Multiple Choice VideoQA, and Text Generation의 8개의 benchmark에서 SFT된 모델들보다도 더 나은 성능을 보였다는 결과
Experiments

: Open-Ended VideoQA results
: 점선 아래는 training free baseline // 그 위는 모두 fine tuning된것들에 대한 결과임
++ 추가 Ablation과, insight들은 추후 수정 예정
반응형