반응형
RL step
- agent 가 정책을 학습하는 과정으로써, reward signal을 최대화하는 방식으로 “유도”해서 학습하는 방식임
- SFT와 엄연히 구분을 해야 한다!

RLHF step
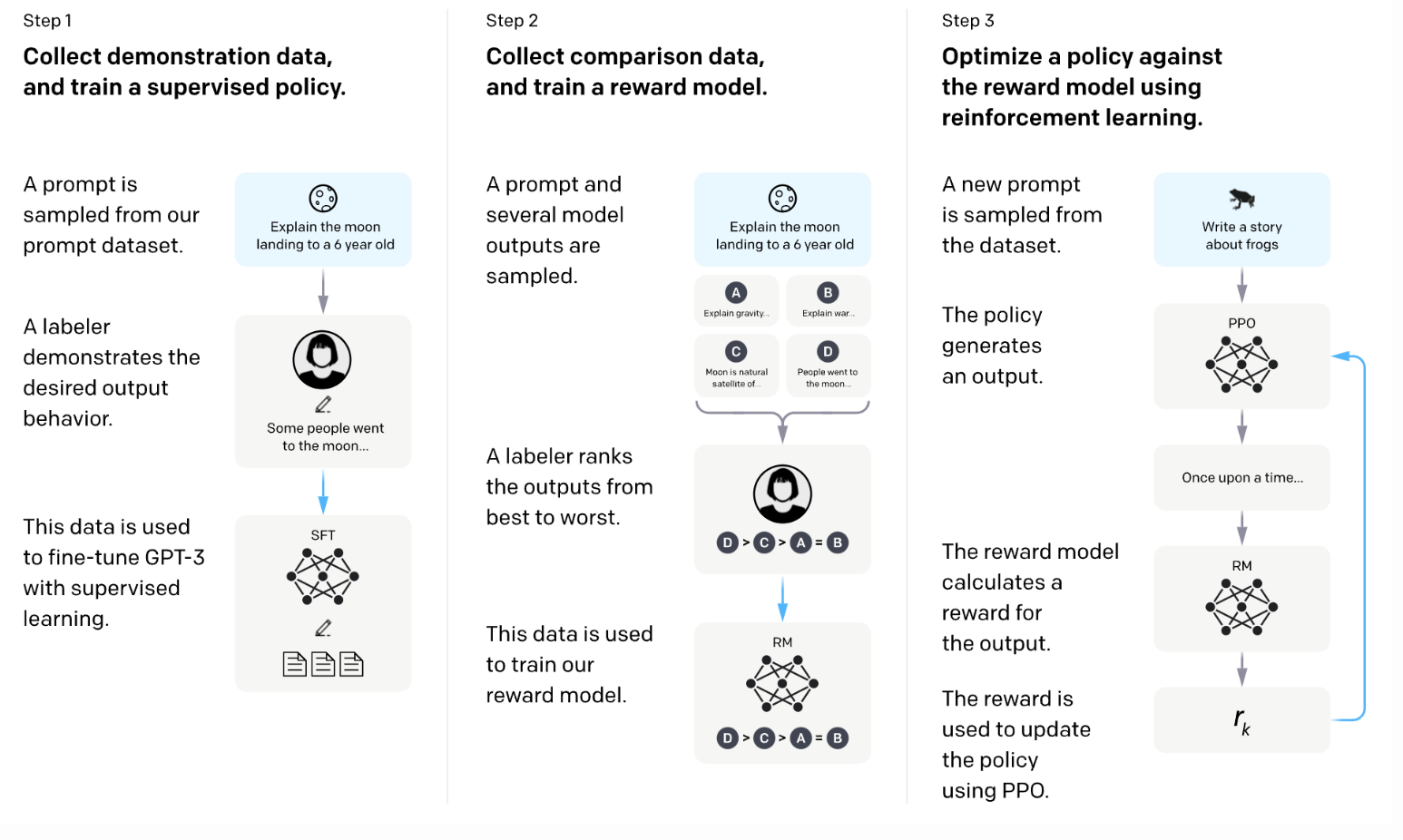
- 첫 번째로, 높은 퀄리티의 human labeled data를 통해 기존의 pretrained model의 supervised fine tuning 진행
- 이후 개별적인 reward model을 학습 (pairwise human preference data 이용)
- Policy Optimization: RL 알고리즘 사용을 통해, reward model을 통해 reward를 측정하고, policy를 지키면서 model은 human preference에 상응하는 reward를 최대화하는 결과를 위해 계속적으로 학습해 나간다.
DPO step
→ reward function modeling하는 것과 RL algorithm 태우는 것 대신에, human preference data 를 통해 직접적으로 model 의 parameter를 갱신하는 작업임
이는 reward model을 사용하지 않았기 때문에 기존의 RL 보다 훨씬 효율적이고, “base” model 과 “optimized” model 두 개를 사용해서 비교함으로써 updating진행하는 것임
- It takes pairs of outputs (preferred vs. rejected) from human annotations.
- It directly optimizes the model by adjusting its output probabilities to favor the preferred response.

반응형