- CLIP-ViT Image encoder에서, text기반으로 decomposition을 하여 각 요소마다 영향력을 분석하는 논문임.
- Image representation을 Image Patches + Model layers + Attention Heads의 sum으로 decomposition한 후, CLIP의 text representation을 사용하여 각 부분이 image representation에 미치는 효과를 자세히 분석하였음.
- 각 요소들을 상세히 분석하여, CLIP에서 그닥 필요하지 않은 부분(=feature)을 제거하여 robust한 zero-shot image segmenter를 만들어 냄.
CLIP-ViT Architecture

$M_{img}$는 img encoder
$(I_i, t_i)$는 image와 text의 batch 쌍을 나타냄
- CLIP-ViT Decomposition

- image representation은 다음과 같이 decomposition된다.

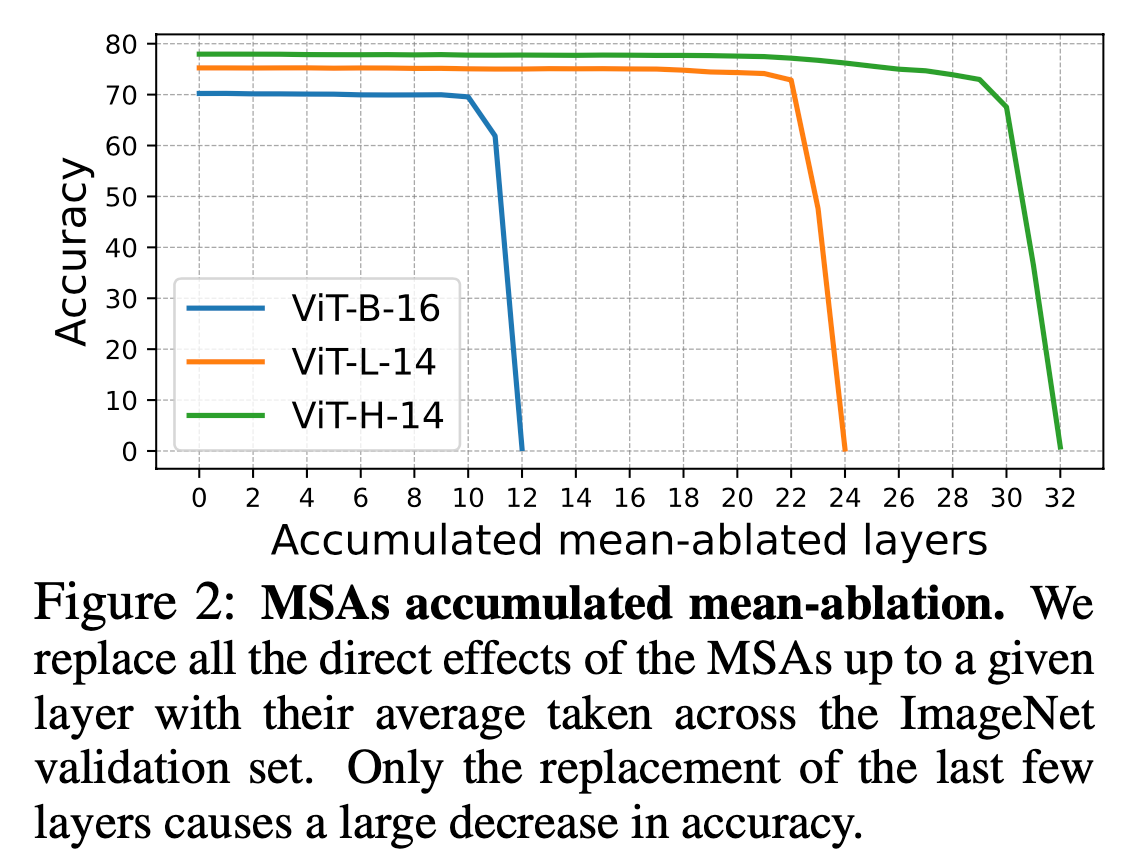
- Mean Ablation방법(= 특정 요소를 제거했을 때와 비교)
- 결과
- MLP는 붙이거나, 떼어도 거의 변화가 없다.

- MSA 에서 마지막 4개의 layer가 직접적으로 큰 효과를 낸다.
cf) fine-grained이란 ?
- 다수의 호출로 하나의 동일한 작업의 결과를 이루어내는 방식
- head와 position을 Fine-grained decomposition하기 (MSA)

$H$ : independent attention heads
$N$ : input tokens
$l$ : layer
${\alpha}$ : attention weights from the class token to the i-th token
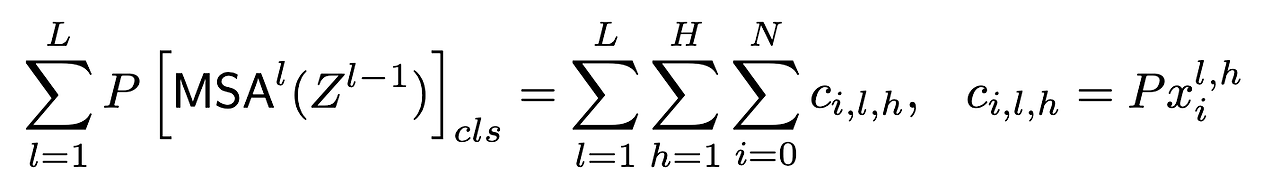
위 식은, 모든 attention block의 전체 영향은, 전체 dimension(l, h, i)의 tensor $c$ 에 대한 결괏값과 동일하다는 것을 의미한다.
예를 들어, 각 head의 영향력을 구하고 싶은 경우 아래 수식 적용

또 다른 예로, image token의 영향력을 구하고 싶은 경우 아래 수식 적용 (i = location)

각 tensor들은 같은 차원(d) representation space로 정하여, 영향력을 비교하도록 하였음
Decomposition into Attention heads
- CLIP의 마지막 4개의 MSA Layer에 주목하여, Layer 내의 개별 head를 text description과 함께 labelling하였음
- 위 table과 같이, 각 Layer에 대해 image의 specific한 측면을 집중해서 보는 여러 개의 head들이 있으며, 각 head들은 그와 연관된 text description을 가지고 있다.
- 각 layer에는 16개의 head가 있으며, 마지막 4개의 layer을 보기 때문에 총 64개의 head를 분석하였음
- head의 영향력을 분석하고 싶은 경우
- $c_{head}^{l, h}$ 를 분석하고 싶은 경우, head의 output을 보았을 때 결과에서 가장 큰 variance를 보일 때의 text description set를 찾아낸다.
- 이를 위해서는, layer $l$과 head $h$가 같은 head output c와, 그와 연관된 input image를 가져온다. 이를 설명하는 head output c에 대한 variance는 다음과 같이 구한다.

해당 식의 경우 closed optimization 문제가 아니므로, greedy 알고리즘을 사용하였다.
즉, 방대한 양의 text description ${t_i}_{i=1}^{M}$에서 greedy하게 몇 개의 text description을 뽑아내어 set $T$를 만든다.
$R$ : representations for the candidate descriptions
$C$ : outputs for head ($l, h$)
- 다양한 applicaiton

head output 과 text 의 similarity를 조사해서 가장 큰 similarity를 기록한 image를 TEXTSPAN 알고리즘을 통해 도출해낸 예시들이다.

head가 특정 property를 보여준다는 점에 기반해서, Image Retrieval 도 가능하다는 것을 보여주는 예시임
Decomposition into image token
- 지금까지는 Image representation을 decompose해서 얻은 각 head가 어느 부분에 contribute했는지를 관찰했다면, 이번에는 representation을 image token으로 decompose하여 “image의 어떤 부분이” text에 기반하여 결과에 미치는지를 분석함.
생각해볼 점
- 설령 MSA의 마지막 4개의 layer가 결괏값에 가장 큰 영향을 미치더라도, 그 이전 layer가 마지막 layer에 어떠한 Information flow를 줘서 도움을 준 것이 아닌가 라는 생각.
(그에 대한 분석이 필요하다)
- 과연 각각의 head가 이렇게 specific한 property를 지니며, 각각의 role을 가지는가?에 대한 의문
- 특정 Head는 여러 property를 가질 수 있다고도 함